这周全球都在热议关税问题,但科技圈的焦点却集中在人工智能领域的一系列大动作上。
周末,Meta公司突然发布了Llama 4系列模型,声称它具备“与生俱来的多模态能力”和“高达千万级别的上下文理解窗口”。他们还首次公开了可以在单张H100显卡上运行的轻量级版本。在此之前,OpenAI公司也宣布他们的O3和O4-mini模型将在未来几周内推出,同时确认由于技术整合和算力部署的问题,原计划的GPT-5模型将推迟几个月发布。
另一边,DeepSeek公司与清华大学的研究团队在本周联合发表了一篇关于模型推理时扩展性的新论文。他们提出了一种叫做“自我原则点评调优”(SPCT)的学习方法,并基于此构建了DeepSeek-GRM系列模型。通过结合一种特殊的奖励机制,这些模型在推理时能够实现能力的扩展,性能接近拥有6710亿参数的大型模型,这暗示着DeepSeek的下一代R2模型即将到来。这周全球都在热议关税问题,但科技圈的焦点却集中在人工智能领域的一系列大动作上。
Meta强势推出Llama 4,多模态与超长上下文成亮点
周六,Meta正式发布了Llama 4系列模型,Llama 4全系采用混合专家(MoE)架构,并实现了原生多模态训练,彻底告别了Llama 3纯文本模型的时代。此次发布的模型包括:
- Llama 4 Scout(17B 激活参数,109B 总参数量,支持 1000 万+ Token 上下文窗口,可在单张 H100 GPU 上运行);
- Llama 4 Maverick(17B 激活参数,400B 总参数量,上下文窗口 100 万+,性能优于 GPT-4o 和 Gemini 2.0 Flash);
- 以及强大的 Llama 4 Behemoth 预览(288B 激活参数,2 万亿总参数量,训练使用 32000 块 GPU 和 30 万亿多模态 Token)。
此次公布的Llama 4 Maverick 和 Llama 4 Scout 将是开源软件。然而,Llama 4 的新许可证对使用有一定限制,例如月活用户超 7 亿的公司需申请特殊许可,且使用时需遵守多项品牌和归属要求。
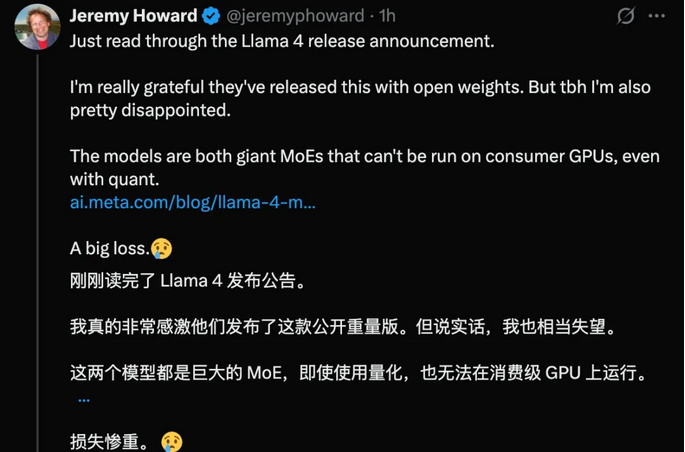
前kaggle总裁,fast AI 创始人Jeremy Howard表示,虽然感谢开源,但Llama 4 Scout 和 Maverick 都是大型 MoE 模型,即使量化后也无法在消费级 GPU 上运行,这对开源社区的可及性来说是个不小的损失
Meta强调,Llama 4 Scout 和 Llama 4 Maverick 是其“迄今为止最先进的型号”,也是“同类产品中多模态性最好的版本”。
- Scout亮点:速度极快,原生支持多模态,拥有业界领先的 1000 万+ Token 多模态上下文窗口(相当于处理 20 多个小时的视频!),并且能在单张 H100 GPU 上运行(Int4 量化后)
- Maverick性能:在多个主流基准测试中击败了 GPT-4o 和 Gemini 2.0 Flash,推理和编码能力与新发布的 DeepSeek v3 相当,但激活参数量不到后者一半
X网友也对Scout模型的性能感到震惊,尤其是其在单GPU上运行并支持超长上下文窗口的能力。
最令人瞩目的是Llama 4 Behemoth。目前Behemoth仍处训练中,不过Meta将其定位为“世界上最智能的 LLM 之一”。这个拥有288B激活参数和2万亿总参数量的“巨兽”,在32000块GPU上训练了30万亿多模态Token,展现了Meta在AI领域的雄厚实力。
有X网友指出了Behemoth训练的性能潜力,强调了它在阶段就已经表现出超越多个最高级模型的能力,例如Claude 3.7 和Gemini 2.0 Pro。
之前,《The Information》在周五报道说,由于投资者们都在敦促大型科技公司展示他们的投资回报,Meta公司计划今年投入高达650亿美元来扩大其人工智能基础设施。
OpenAI确认O3和O4-mini即将推出,GPT-5的免费策略引起广泛关注
在Llama 4发布的同时,OpenAI的首席执行官Sam Altman也在社交媒体上确认,O3和O4-mini将在接下来的几周内发布,而GPT-5则计划在未来几个月内与公众见面。
在关税问题成为焦点的一周,人工智能领域也“暗潮涌动”:Llama 4发布了,O3和O4-mini也要来了,DeepSeek R2和GPT-5也离我们不远了吗?
虽然目前还没有更多关于O3和O4-mini的详细信息,但是Altman表示,OpenAI在很多方面都对O3模型进行了显著的改进,相信一定会让用户非常满意。
在关税问题成为焦点的一周,人工智能领域也“暗潮涌动”:Llama 4发布了,O3和O4-mini也要来了,DeepSeek R2和GPT-5也离我们不远了吗?
实际上,GPT-5的功能和发布时间才是市场最为关注的重点。根据Altman透露,GPT-5将整合语音识别、Canvas绘图、搜索功能以及更深层次的研究能力等多项功能,成为OpenAI统一模型战略的核心组成部分。
这意味着GPT-5将不再是一个单独的模型,而是一个集成了多种工具和功能的综合性系统。通过这种整合,GPT-5将能够自主选择使用合适的工具,判断何时需要进行深入思考,何时可以快速给出答案,从而能够处理各种复杂的任务。OpenAI的这一举措旨在简化其内部的模型和产品体系,使人工智能真正实现随时可用、便捷高效。
更令人兴奋的是,GPT-5将向免费用户开放无限的使用权限,而付费用户则能够体验到智力水平更高的版本。此前,Altman在与硅谷知名分析师Ben Thompson的深入对话中提到,由于DeepSeek的影响,GPT-5将考虑让用户免费使用。
不过,对于GPT-5的发布时间一再推迟,有网友制作了以下这个时间表来开玩笑。
DeepSeek携手清华发布新论文
DeepSeek与清华大学的研究团队本周联合发布了一篇关于推理时Scaling的新论文,提出了一种名为自我原则点评调优(Self-Principled Critique Tuning,简称SPCT)的学习方法,并构建了DeepSeek-GRM系列模型。这一方法通过在线强化学习(RL)动态生成评判原则和点评内容,显著提升了通用奖励建模(RM)在推理阶段的可扩展性,并引入元奖励模型(meta RM)进一步优化扩展性能。
SPCT方法的核心在于将“原则”从传统的理解过程转变为奖励生成的一部分,使模型能够根据输入问题及其回答内容动态生成高质量的原则和点评。这种方法包括两个阶段:
- 拒绝式微调(rejective fine-tuning)作为冷启动阶段,帮助模型适应不同输入类型;
- 基于规则的在线强化学习(rule-based online RL)则进一步优化生成内容,提升奖励质量和推理扩展性。
为了优化投票过程,研究团队引入了元奖励模型(meta RM)。该模型通过判断生成原则和评论的正确性,过滤掉低质量样本,从而提升最终输出的准确性和可靠性。
实验结果显示,DeepSeek-GRM-27B在多个RM基准测试中显著优于现有方法和模型,尤其是在推理时扩展性方面表现出色。通过增加推理计算资源,DeepSeek-GRM-27B展现了强大的性能提升潜力,证明了推理阶段扩展策略的优势。
这一成果不仅推动了通用奖励建模的发展,也为AI模型在复杂任务中的应用提供了新的技术路径,甚至可能在DeepSeek R2上能看到该成果的展示。
有海外论坛网友调侃道,DeepSeek一贯是“论文后发模型”的节奏,竞争对手Llama-4可能因此受压。




还没人哔哔!你可以做第一个~